Introduction
My first unsupervised model. There really isn’t much there was to say to preface the code either than the data set was obtained through UCI and that the process was surprisingly fun. The set was a list of customers, their attributes, and whether or not they were approved for a credit card. The goal was to determine whether or not the customers lied to be approved based solely on the information that was given on their application.
Code
The first step was the creation of the self organizing map. This was easily executed with a couple lines of code.
The
#Training
from minisom import MiniSom #the SOM function
ms = MiniSom(x = 10, y = 10, input_len = 15, sigma = 1, learning_rate = .5)
ms.random_weights_init(X) #X is the independent variable
ms.train_random(data = X, num_iteration = 150) #Training the model
The second step was to plot the map, and place red circles on the nodes with customers that were denied, and green x’s where they were approved.
from pylab import bone,pcolor,colorbar, plot, show
bone()
pcolor(ms.distance_map().T)
colorbar()
markers = ['o','x']
colors = ['r', 'g']
for i, x in enumerate(X):
win = ms.winner(x)
plot(win[0] + 0.5,
win[1] + 0.5,
markers[Y[i]],
markeredgecolor = colors[Y[i]],
markerfacecolor = 'None',
markersize = 10,
markeredgewidth = 2)
show()
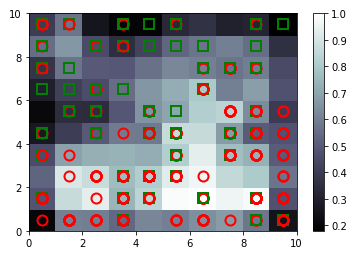
The results of the map are rather intuitive. The lighter colors are associated with a greater distance to the winning node. Since the markers on the graph represent whether or not the customers were approved, this raises a few eyebrows if there are approved customers with relatively high distances. These potential frauds were listed with the following code.
mapping = ms.win_map(X) #Finding customers associated to winning nodes
frauds = np.concatenate((mapping[(6,1)],mapping[(8,1)]), axis = 0) #Inputs are the most suspicious neurons
frauds = sc.inverse_transform(frauds) #Gives the id numbers for the possible cheaters
Results
Having a list of potential fraudulent customers is great, however a further step could be taken to determine whether or not other, or future customers, are as well. Utilizing my previous knowledge of Artificial Neural Networks made this section rather direct.
customers = data.iloc[:, 1:].values
potential_fraud = np.zeros(len(data)) #Creates an array of zeros that will
for i in range(len(data)): #Change from a 0 to a 1 if they are a potential fraud
if data.iloc[i,0] in frauds:
potential_fraud[i] = 1 #This creates the dependent variable to train the ANN
# Importing the Keras libraries and packages
from keras.models import Sequential
from keras.layers import Dense
# Initialising the ANN
classifier = Sequential()
# Adding the input layer and the first hidden layer
classifier.add(Dense(units = 2, kernel_initializer = 'uniform', activation = 'relu', input_dim = 15))
# Adding the output layer
classifier.add(Dense(units = 1, kernel_initializer = 'uniform', activation = 'sigmoid'))
# Compiling the ANN
classifier.compile(optimizer = 'adam', loss = 'binary_crossentropy', metrics = ['accuracy'])
# Fitting the ANN to the Training set
classifier.fit(customers, potential_fraud, batch_size = 1, epochs = 2)
# Predicting the probabilities of frauds
y_pred = classifier.predict(customers)
y_pred = np.concatenate((data.iloc[:, 0:1].values, y_pred), axis = 1) #Brings array of prediction values and customer IDs
y_pred = y_pred[y_pred[:, 1].argsort()] #Ascending list of fraud probabilities
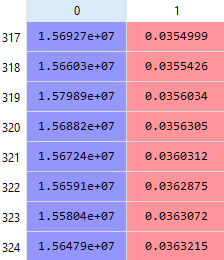
The customers were listed from an ascending order of probability of fraudulence. Towards the end the highest probability reached only 18%, which tells me the winning nodes I chose were either not the best, or the other customers were some of the most honest people on the planet.