Introduction
Artificial Neural Networks were the first type of supervised deep learning model that I have studied. The thing I found most interesting about them is the back propagation model they utilize since my knowledge of networks prior to that was only feed forward, and found the method of updating weights remarkable. The data used was a sample churn model data found on Kaggle. This data set organized thousands of bank customers by about 10 criteria with the goal of predicting whether or not they will leave the bank.
Code
I found ANN’s to be rather straight forward. When choosing an API that handles tensor math, I decided to go with Keras mainly because I had used Tensorflow previously, and wanted to try something new.
After cleaning the data, turning categorical data into numerical, and breaking it into dependent and independent variables, I began to build the ANN.
import keras as k
from keras.models import Sequential
from keras.layers import Dense
#Initialization of ANN
classifier = Sequential()
classifier.add(Dense(output_dim = 6, init = 'uniform', activation = 'relu', input_dim = 11))
# Adding the second hidden layer
classifier.add(Dense(output_dim = 6, init = 'uniform', activation = 'relu'))
# Adding the output layer
classifier.add(Dense(output_dim = 1, init = 'uniform', activation = 'sigmoid'))
# Compiling the ANN
classifier.compile(optimizer = 'adam', loss = 'binary_crossentropy', metrics = ['accuracy'])
classifier.fit(X_train, y_train, batch_size = 10, nb_epoch = 100)
Other than changing the output dimensions, I felt as though there was not much “freedom” with making this network my own. The one thing I would like to experiment with more would be the optimizer function. I utilized adam since it was the most reliable from what I have read, however I have not seen as much use in nadam. Although the Nesterov momentum approach used for this optimizer may not produce wildly different results, I still feel it is worth exploring.
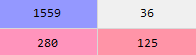
Results
Using a confusion matrix to determine the number of correct predictions, the model yielded an accuracy of 68.4%. The results were fine, but could be improved with a little tuning.